NeRF只能对static scene学习,因此,为了同大多数dynamic NeRF一样,本文也是增加一个deformation field将observation frames先转换到canonical frames,然后再使用NeRF进行学习重建。
一名在读研究生,新视角合成方向(NeRF+LF)
NeRF只能对static scene学习,因此,为了同大多数dynamic NeRF一样,本文也是增加一个deformation field将observation frames先转换到canonical frames,然后再使用NeRF进行学习重建。
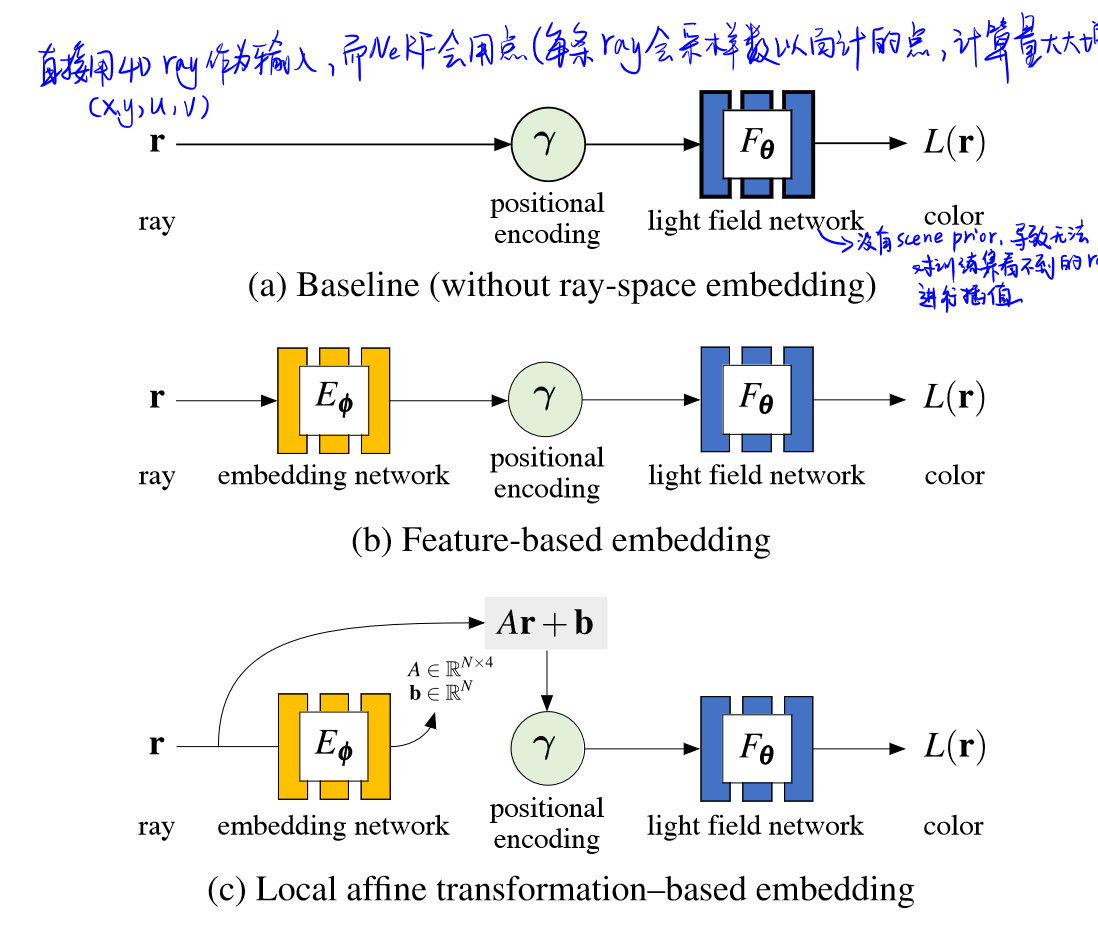
本文使用的是4D LF表达方式。可直接从(x,y,u,v)得到color+density,而不用像NeRF那样需要hundreds of sampled point。
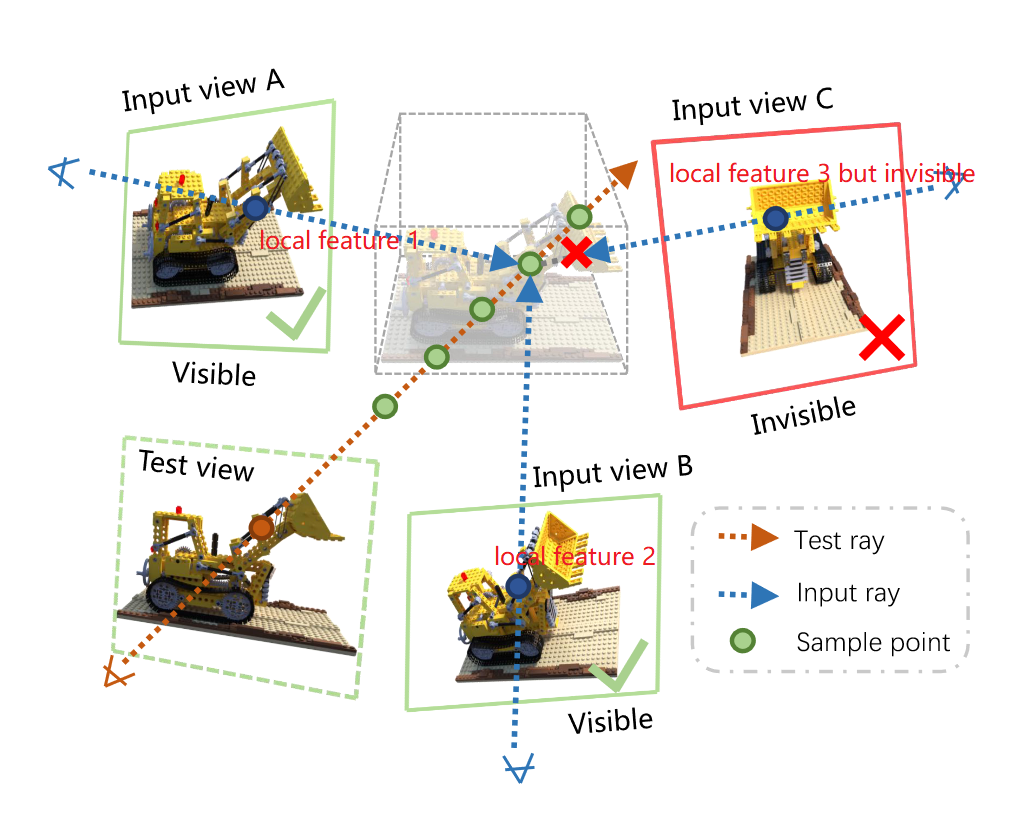
本文如果没有可见性向量,那么就是最基本的IBR渲染,即将图像的特征输入NeRF进行学习。但本文还额外增加了一个可见性向量,用于表示当前input view上的点对target view的重要性。
CVPR 2022 best paper finalist
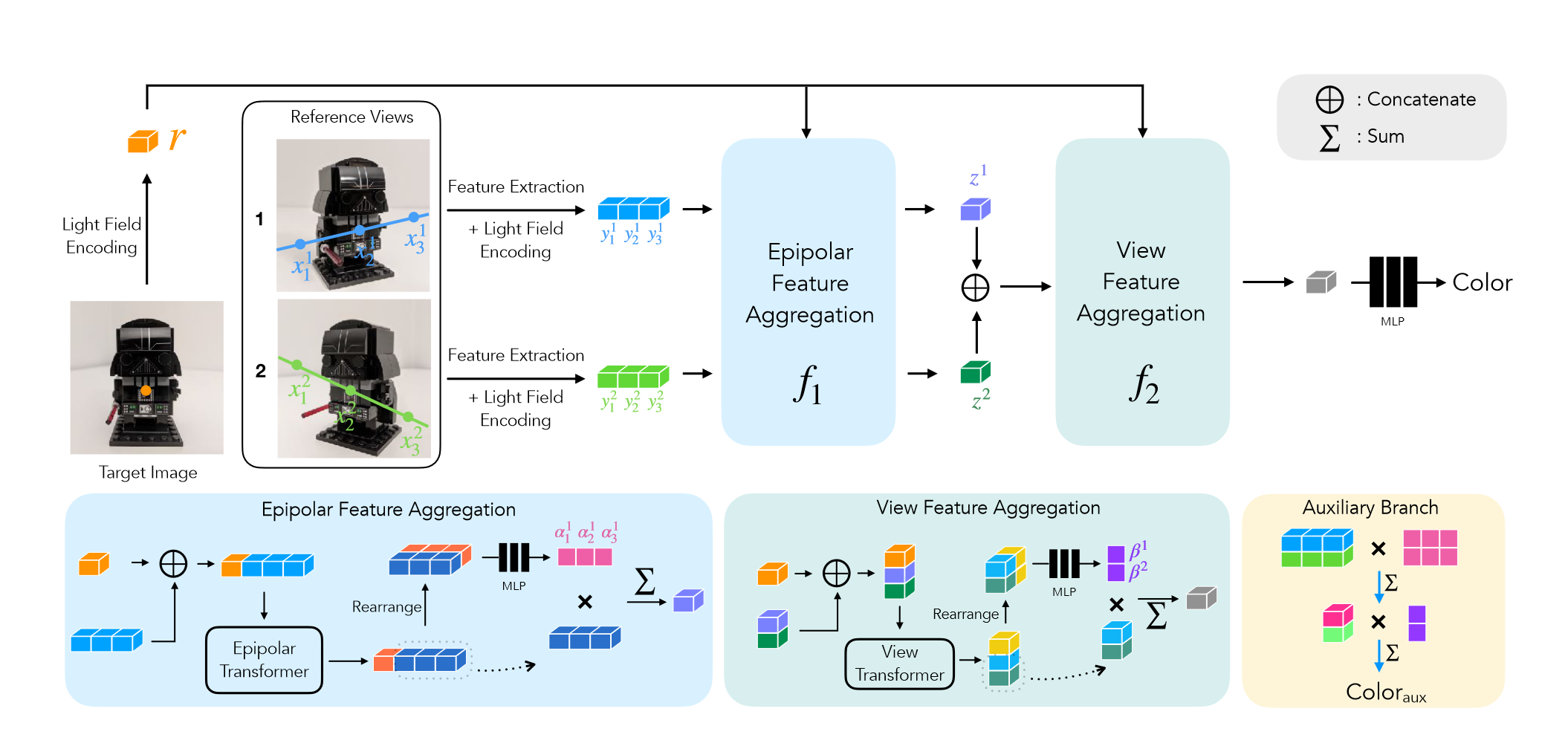
本文与IBRNet很相似,基于IBR(但是加入了对极几何约束)。另外,也是使用了类似于像素对其特征进行融合,只不过各个point&view融合的权重是由self-attention计算的。

主要是用cone tracing代替ray tracing,消除不确定性。使用多元高斯函数表示一段截头圆锥,并提出IPE(Integrated Positional Encoding)替代原始NeRF中的PE。
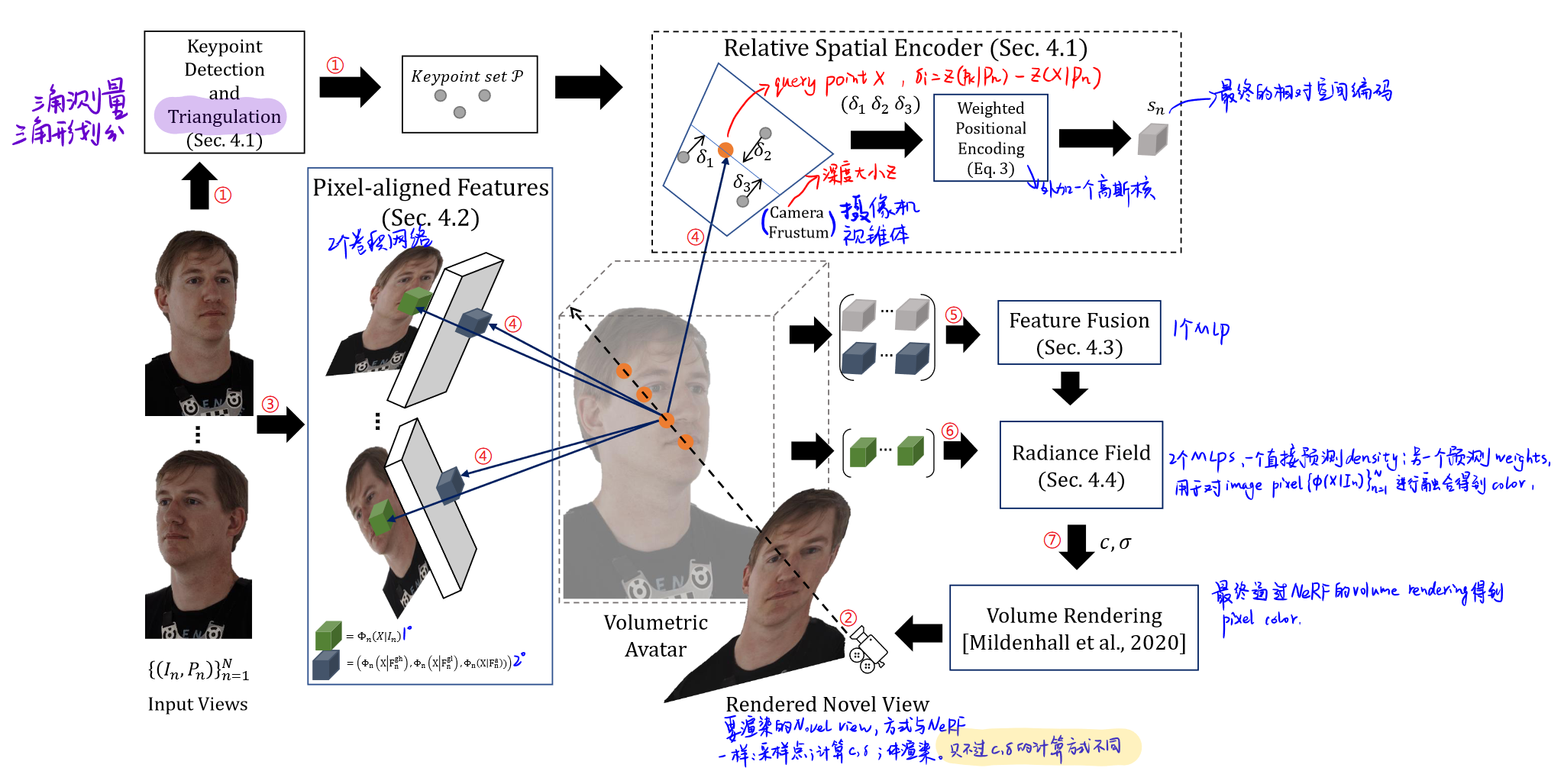
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
通过用3D关键点对query point进行相对空间编码,解决全局编码对细节重建不好的缺点;以及使用pixel-aligned feature实现细节重建。
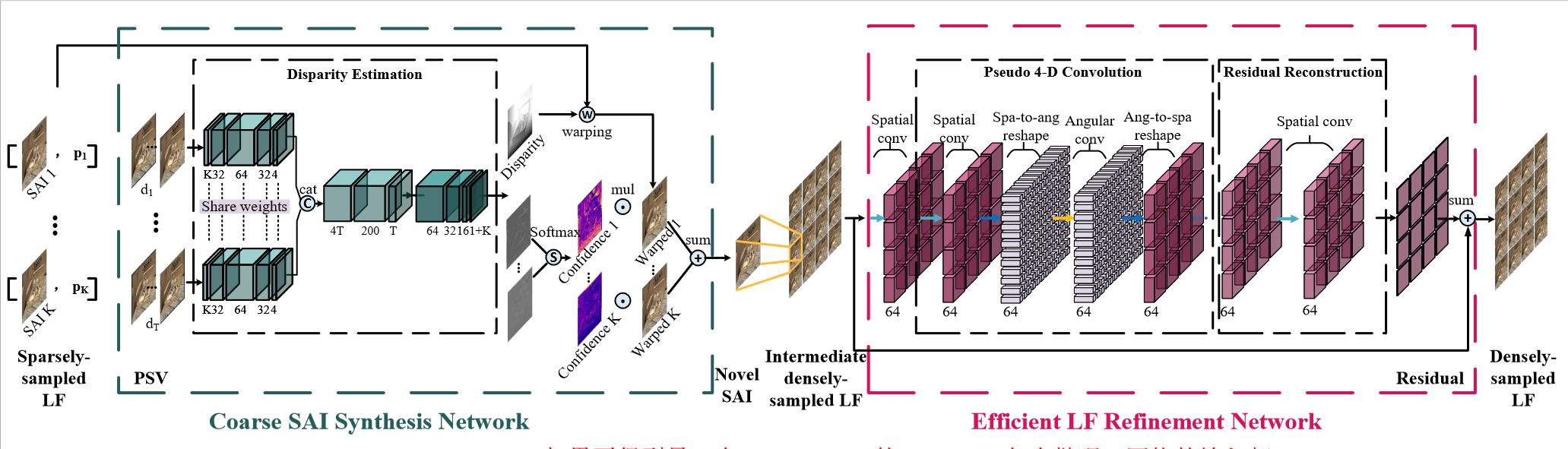
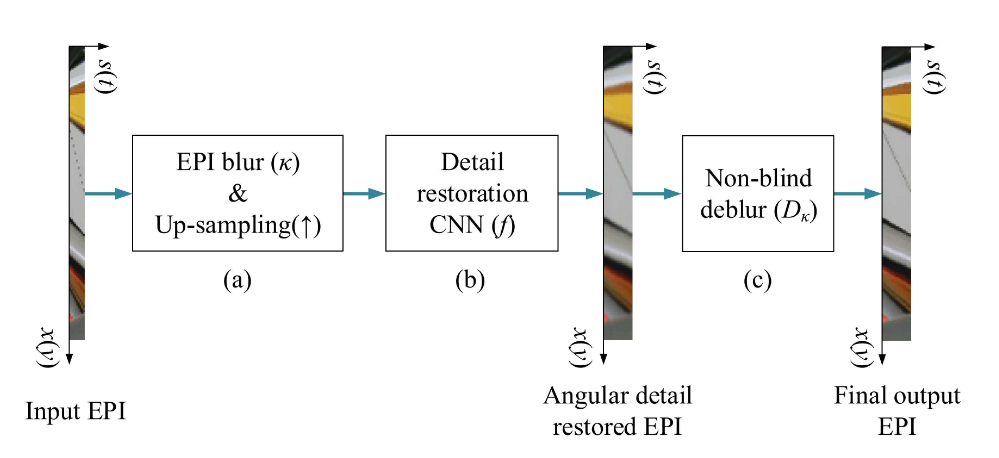
K个sampled LF(),PSVs设置为T个(),则对每个novel view来说会构建个PSVs,然后通过下图中的Disparity Estimation会得到novel view对应的1个Disparity和K个confidence map;K个sampled LF + 1个Disparity得到K个warped LF;K个confidence map与K个warped LF融合得到intermediate LF,经过refine(pseudo 4D convolution + residual)得到novel view。
Jing Jin, Junhui Hou, Hui Yuan, Sam Kwong
City University of Hong Kong, Shandong University
AAAI 2020
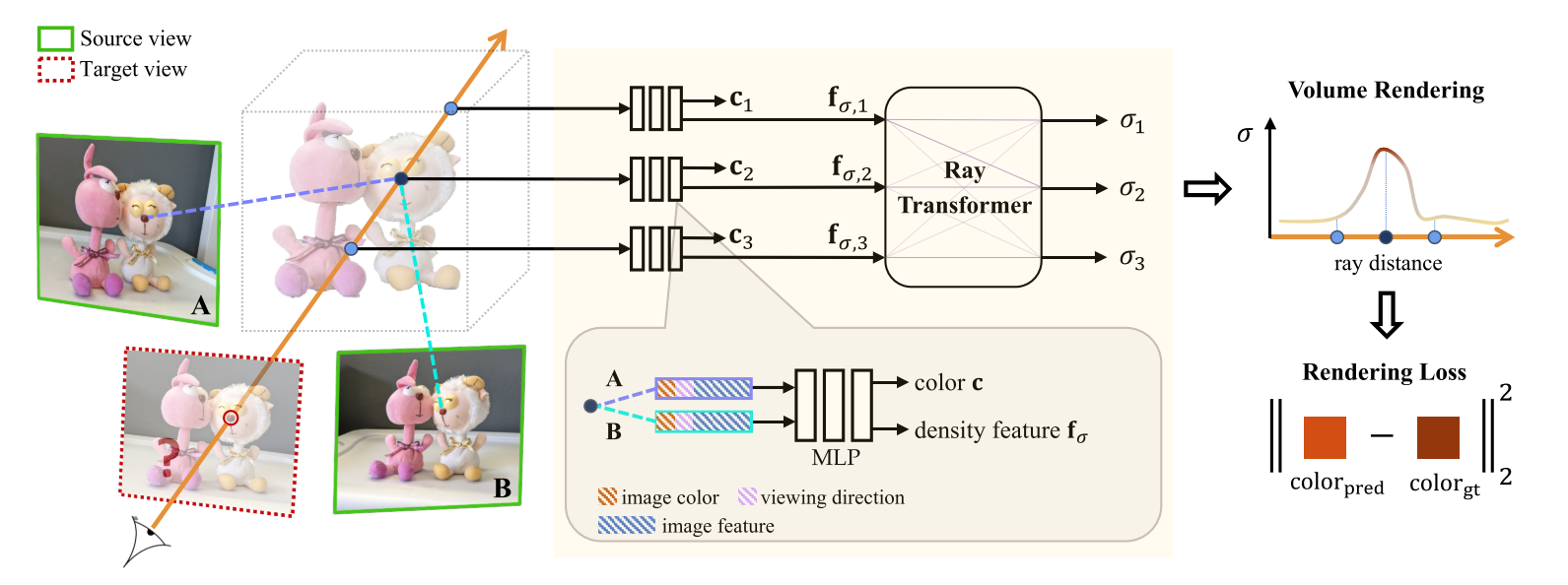
渲染某个target view时,会使用与其在空间位置上相邻的N个input views作为参考。另外还使用了Transformer Ray,即将cast ray上的采样点视为序列点。