本文的稀疏是指仅2个视角,且这两个视角只有很少的重叠区域。使用CNN(high resolution) + Self-Attention(low resolution)的形式得到2个视角各自的像素对齐特征;提出极线采样策略优化像素对齐特征下的采样效果,并使用多视角特征匹配进一步提升采样质量;使用cross-attention得到代表代理几何的, 然后通过一个较小的MLP预测颜色。
How to do Research - Writing - Introduction
三图五问:WHAT+WHY+HOW,
- What's the problem? (WHAT figure)
- What have others done?
- What's the gap? (WHY figure)
- What have you done? (HOW figure)
- What do you contribute?
文章名称:Learning to Render Novel Views from Wide-Baseline Stereo Pairs
What's the problem? (WHAT figure)

What have others done? & What's the gap? (WHY figure)
NeRF方法能够实现照片级图像渲染→需要大量视角图像→本文探讨使用极其稀疏的图像进行视角合成的可能性。
gap: 现存的稀疏新视角合成方法(pixelNeRF, IBRNet, MVSNeRF etc.)大多限制在物体级场景object-level scene的视角合成,以及在3-10张输入下的小基线渲染。本文瞄准由许多具有复杂几何及遮挡的物体所组成的真实世界场景,且仅使用2张具有很少重叠区域的输入图像。

What have you done? (HOW figure)
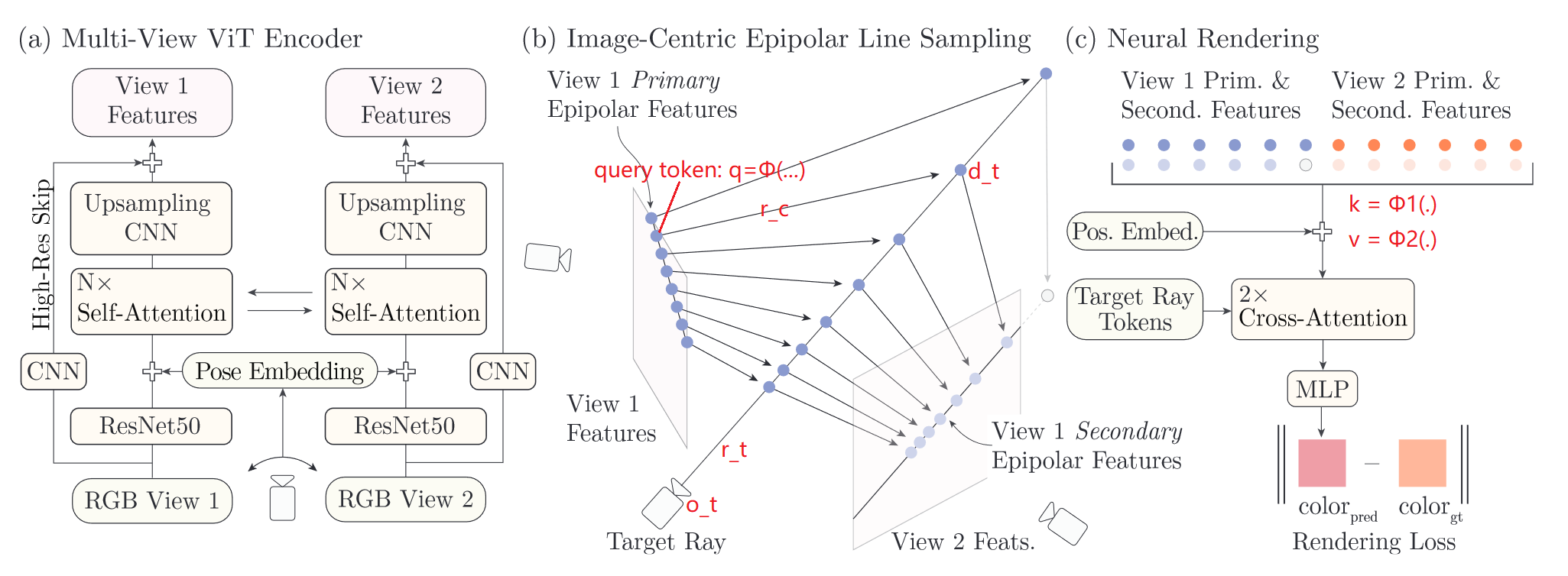
本文,提出一个新方法去解决这些挑战:
- 提出一个多视角视觉Transformer - multi-view vision transformer;
- 提出一个高效的可微分渲染器efficient differentiable renderer;
multi-view vision transformer
用于计算每个输入图像的像素对齐特征。和先前的单目图像编码器相比:
- 将相机姿态信息作为输入,能够更好地推理/解释场景几何;
- 结合高分辨率CNN和低分辨率vision transformer,兼顾memory、computational和performance;
- 使用多视角特征匹配进一步提升在两张图像中都被观察到的点的几何信息;
efficient differentiable renderer
现存方法使用体渲染volume rendering导致十分耗时。另外,像pixelNeRF、MVSNeRF在计算3D采样点对应的特征时,由于透视投影不是线性的,导致特征图上有些点被多次采样,有些点一次也没被采样。因此,这样的采样策略不能很好地利用像素对齐特征图。
在极线上进行采样,并使用多视角特征匹配在另一幅图上也进行采样。
loss & regularization
代表像素对应的极线上的所有采样点的深度均值。
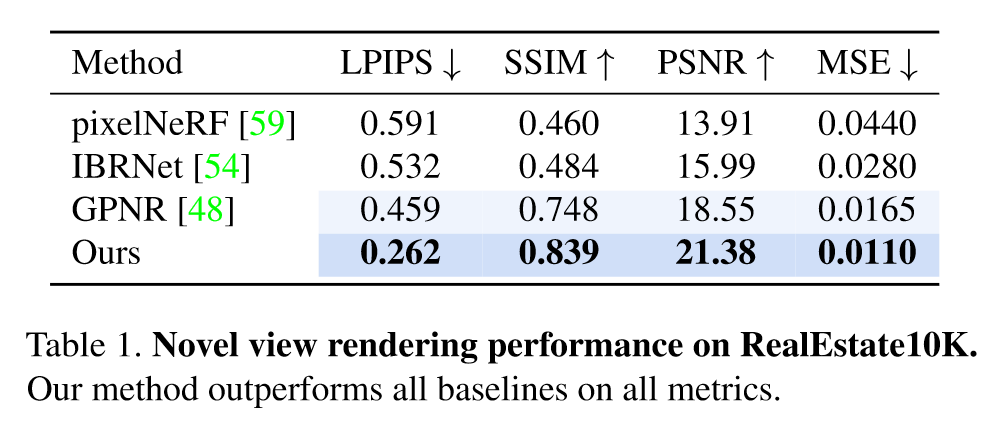
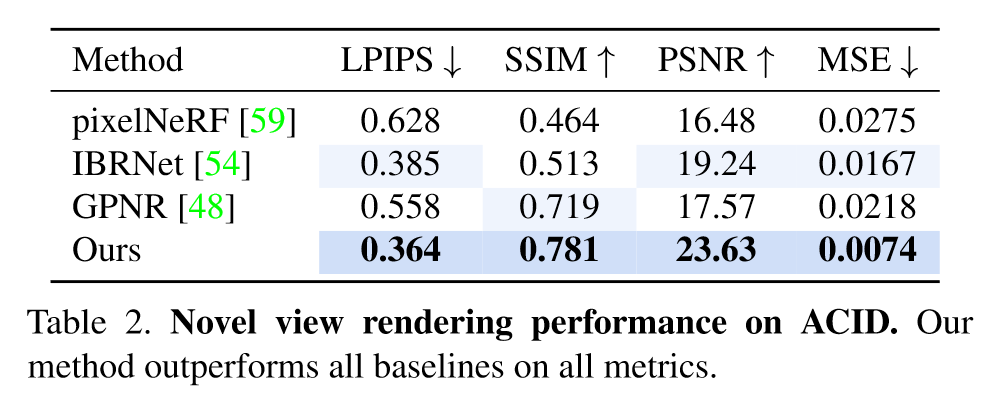
Results
- 数据集:RealEstate10K-indoors、ACID-indoors&outdoors;
- baselines:使用像素对齐特征 (pixelNeRF、IBRNet),基于patch的泛化渲染方法GPNR。
- 评价指标:LPIPS、PSNR、SSIM、MSE