本文要解决的问题是由于NeRF对geometry的重建效果不好,从而导致视角合成质量差的情况。geometry效果不好有多种情况,如输入视角少sparsr input views、数据/视角本身问题等。本文不是解决稀疏输入,应该属于后者,本文利用多种损失约束geometry,主要是MVS。
weekly papers:
Panoptic Lifting for 3D Scene Understanding with Neural Fields:2D的全景分割精度不高(语义分割、实例分割),提升到3D空间并利用几何约束,再渲染得到2D的全景分割,这间接提升分割质量。
DyLiN: Making Light Field Networks Dynamic:提出一个动态NeRF模型DyLiN,一个MLP将t维度embed、一个MLP变到hyperspace,还有一个Deep Res MLP回归颜色和体密度;提出CoDyLiN,多了场景属性输入,并经过各自的MLP加入到DyLiN框架上,实现场景属性编辑。另外,使用了student-teacher知识蒸馏。
Neural Fields meet Explicit Geometric Representations for Inverse Rendering of Urban Scenes|[project page]:没仔细看,可实现重打光relighting、插入物体等功能。用一个Neural intrinsic field利用hash编码估计空间位置的等属性,用HDR Sky Dome估计某个方向的光照强度,后续操作基于目前重打光的主流方法BRDF实现。
: Dual-Camera Defocus Control by Learning to Refocus|[project page]:一个比较实用的工作,利用目前智能手机广泛配备的广角和超广角镜头实现重聚焦refocused、去模糊deblurred、浅景深shallow DoF等功能。refocused可理解为摄后对焦,商用光场相机Lytro的卖点(可惜已不再);此处的deblurred是指失焦模糊defocus;浅景深是将背景模糊,突出前景,即各大手机厂商追求的人像拍摄模式(手机和专业相机没法比,大多是通过算法实现,而不是硬件)。但是这篇论文只看了摘要和引言,主要是对这方面的工作不太了解,仅是弄懂refocused、defocus、DoF等专业名词就耗费了不少时间,暂且跳过。
BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis|[project page]:匿名作者,结合多个先前工作(Mip-NeRF 360、INGP、VolSDF)实现快速渲染,并且能够导出mesh。整体过程包括NeRF-like的SDF构建、SDF+Cube Marching得到mesh、使用有球形高斯分布的mesh vertex训练一个新的appearance model以加速和提升质量。代码未开源!
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis:下面重点分享这篇
MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo:原来看过的,但没仔细看,这周重新看了下,用多视几何约束进行泛化。
paper title
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
相似文献:
- Point-NeRF: Point-based Neural Radiance Fields:用点云的geometry监督。
- Harnessing Low-Frequency Neural Fields for Few-Shot View Synthesis:用低频NeRF产生的geometry监督。
- Depth-Supervised NeRF for Multi-View RGB-D Operating Room Images:用RGB-D的深度信息作为监督
问题
针对NeRF的inaccurate geometry导致渲染图象质量不好,inaccurate geometry是由于sparse input views导致的(欠约束)。
解决方法
重点是各种损失/约束的使用,包括特征匹配位置损失、对极损失、渲染损失、photometric consistency loss、深度平滑损失。
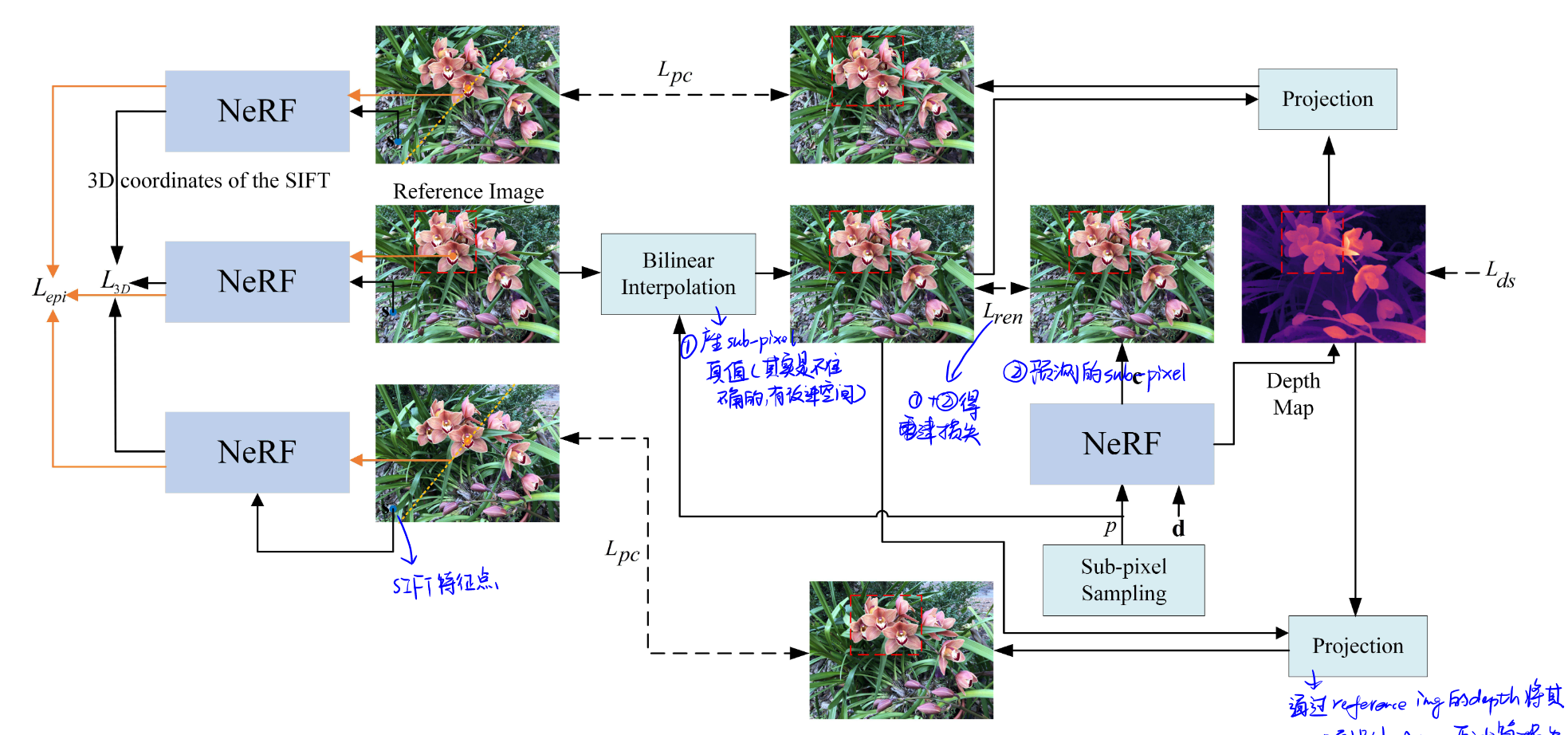
给定三个input views,其中一个作为reference view,分别记为,以及一个NeRF模型。2D pixel coordinate对应的3D coordinate计算公式:
特征匹配位置损失(Positions of matched features loss):SIFT,原理?匹配的特征点对(3D coordinate):。
对极损失(Epipolar loss):对极约束
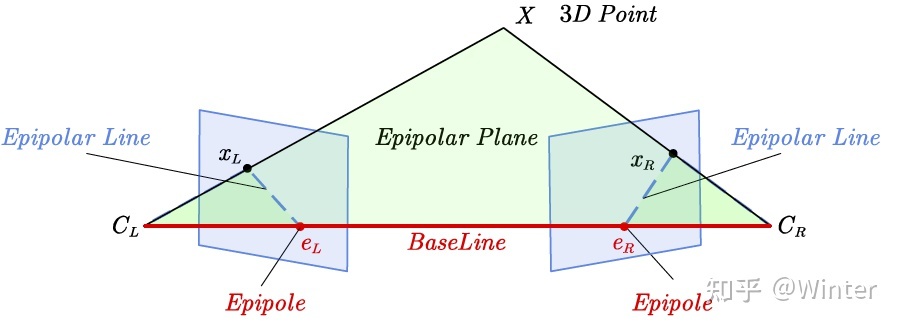
说明:图片来源自知乎@Winter
渲染损失(Rendering loss):patch-based、加偏移offset产生sub-pixel。真值使用bilinear interpolate产生,与预测值做loss。
多视角之间的photometric consistency constraint: patch-based、消除NeRF中的shape-radiance ambiguity(NeRF++)。核心是反投影,3D点到2D点的变换。
深度平滑损失:较大的图像梯度意味着深度不连续,因此
结果
不同方法对比:
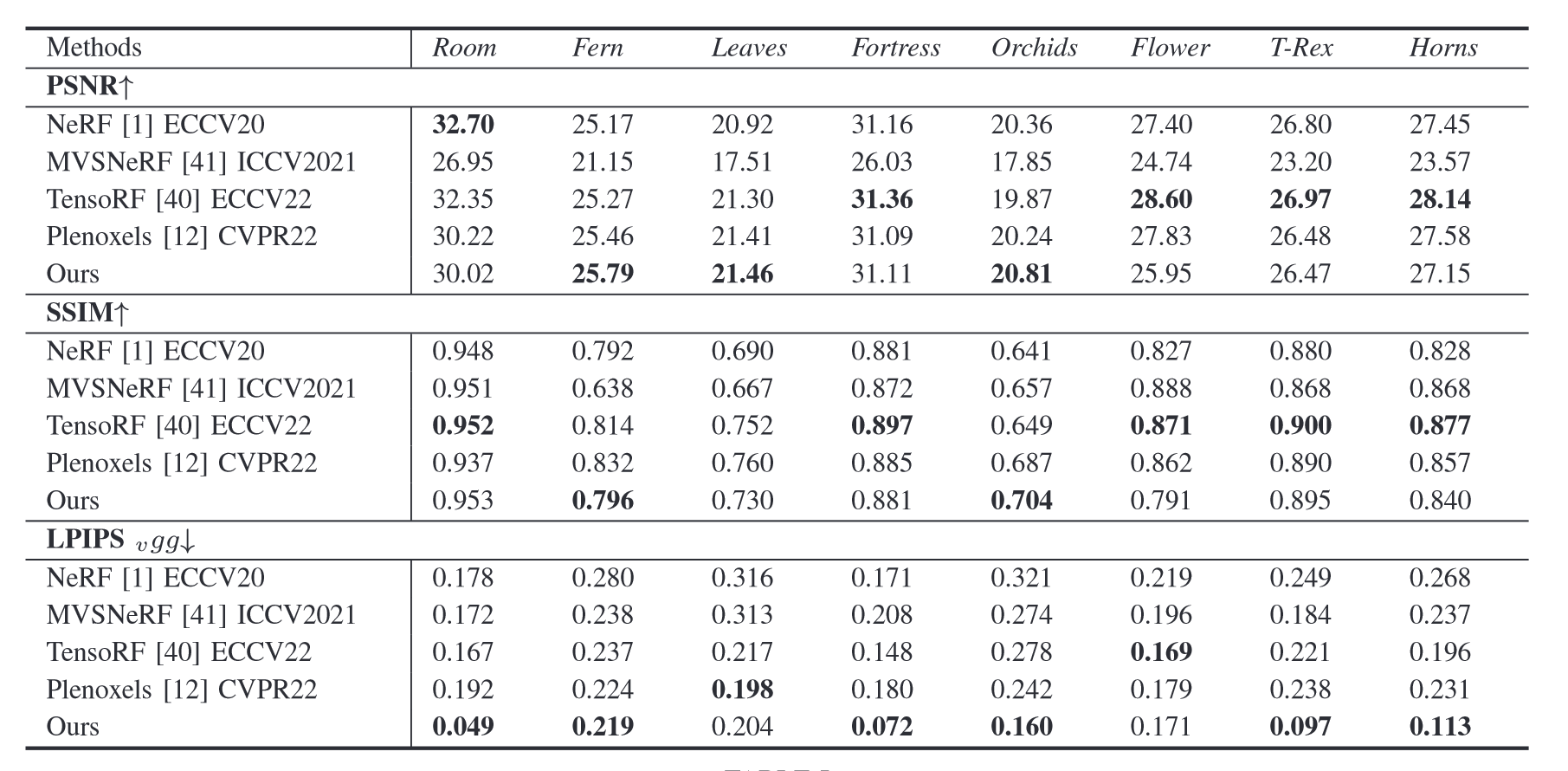
在LPIPS上具有较大优势。
消融研究:

每个损失对结果均有提升,但特征匹配位置损失和亚像素渲染损失提升最明显。
