HeadNeRF利用NeRF的高保真和多视图一致性解决传统3DMM对人脸细节重建效果差(如头发、耳朵等),以及解决用GAN结合3DMM能部分程度增加细节但无法保证多视图一致性的缺点。NeRF的一大缺点是速度慢,因此本文提出2D neural rendering ,本质就是不直接预测颜色,而是通过体渲染得到较小的特征图,再利用渲染得到高保真人脸图像。
weekly papers:
- HeadNeRF: A Real-time NeRF-based Parametric Head Model:CVPR 2022
- NeRF-Supervised Deep Stereo:CVPR 2023。将NeRF作为数据工厂,生成带标签的是数据用于其它Deep Stereo模型训练。
HeadNeRF: A Real-time NeRF-based Parametric Head Model
基于NeRF的实时参数化头部模型 CVPR-2022 中科大
看这篇的原因是需要审一篇基于本文的改进工作。
preliminaries
参数化人脸/头部模型,是指在低维空间对人脸/头部编码,可理解为对大量人脸数据进行降维处理(PCA)得到一组基向量/参数,用这些向量的线性组合表示人脸/头部。经典工作是三维可变形人脸模型3DMM,主要是形状、纹理等系数的估计。
《2D图像→3D模型(优化对象)→2D图像》的过程。先初始化3D人脸模型,再投影到2D,并用2D真值监督优化。
prior works problem
参数化人脸/头部模型的早期工作主要使用拓扑均匀的人脸模板网格mesh对3D人脸进行建模(即对应上面的3D模型),通常忽略了非人脸部分,如头发和牙齿。
DL的发展,2D GAN可以在没有3D模型的情况下直接生成照片级人脸图像,一些方法引入语义解耦约束实现用户控制下的人脸图像生成。但是,无法实现多视角一致性。
solution
NeRF可实现高保真图像,并且其优化的隐式体积表征具有多视角一致性。因此,使用NeRF的隐式3D模型替换拓扑均匀的人脸模板网格mesh(或者GAN),称为基于NeRF的参数化人体。贡献1:提出用NeRF作为3D人脸模型替换掉传统的3D textured mesh。
Overview of HeadNeRF:
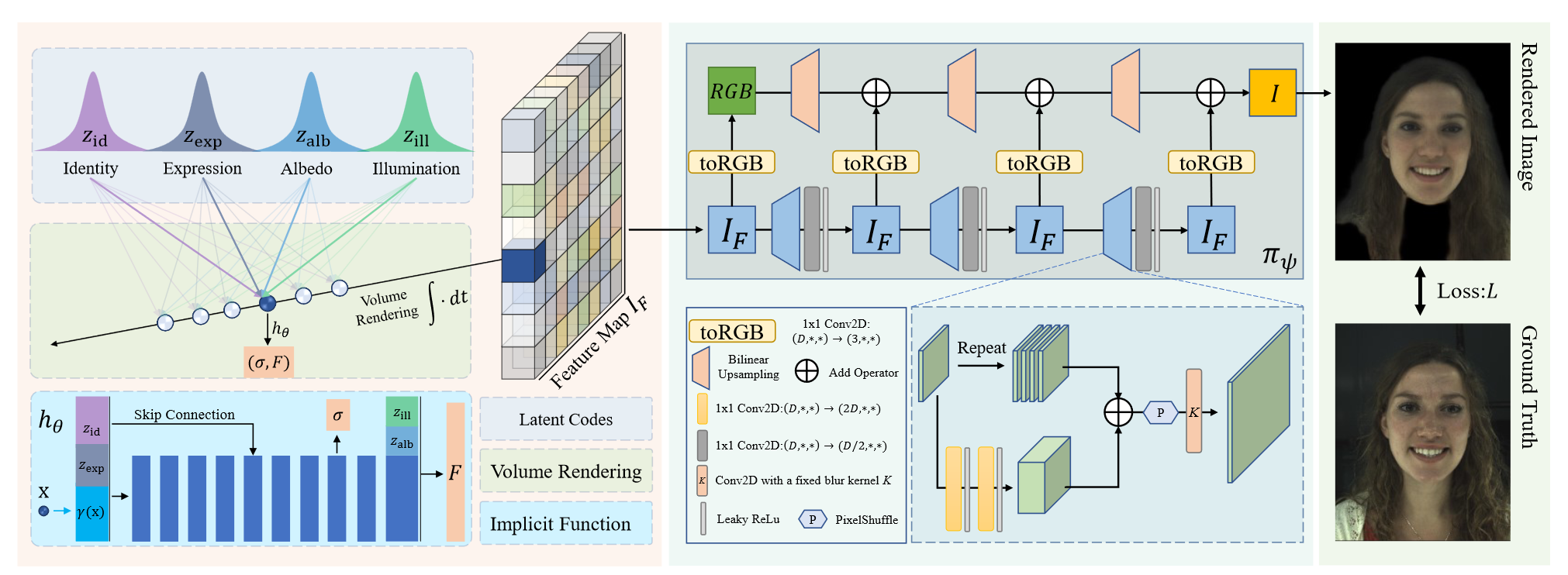
使用3DMM初始化每张图像各自的latent codes:,并在优化过程中被微调(通过一个约束),目的一是优化人脸外观和几何、二是恢复3DMM无法对头发和牙齿等部分表示的缺点。
贡献2:NeRF的计算速度太慢,提出2D神经渲染并整合到NeRF的渲染过程中去。具体是隐式模型不直接回归颜色,而是回归特征,并且是一个低分辨率的特征图,通过2D神经渲染直接将回归到预测图像。
关于每张图像的rigid transformation ,目的是将所有图像都对齐到中心,并且将作为图像的外参,在部分需要用到。
loss:
experiment
2D neural rendering的消融对比:更快更好(实时的关键)
NeRF-based:实现高保真的保障(恢复头发、耳朵等部分)。
消融研究包括感知损失、2D neural rendering、FFHQ数据集的使用,以及解耦控制实验,分别调整人脸的latent code,观察渲染结果。
limitations
训练数据不足以覆盖各种情况,导致泛化性弱。
训练数据中的人几乎没有带头盔(类似的情况),导致很难渲染新的带头盔的图像。
训练数据仅包含4种光照,导致改变光照属性时,渲染结果不连续。
Question
每张人脸图像会通过NL3DMM初始化相应的latent code: ,对于部分射线上不同的3D采样点,其latent code是如何计算的?
NeRF-Supervised Deep Stereo
task: Depth from stereo,即从两张图像中计算深度。本文不是对现有的depth from stereo工作的直接改进,而是利用NeRF为这些工作产生更多的带标签数据,从而提升性能(泛化性和准确性)。
手工设计的算法→深度学习(需要大量带标签数据)。一是自监督学习,但自监督损失对病态情况无效,如遮挡、非朗播表面;二是利用合成数据集,但存在域偏移问题。
本文利用NeRF产生训练数据,为了应付遮挡等情况,使用triplet stereo。
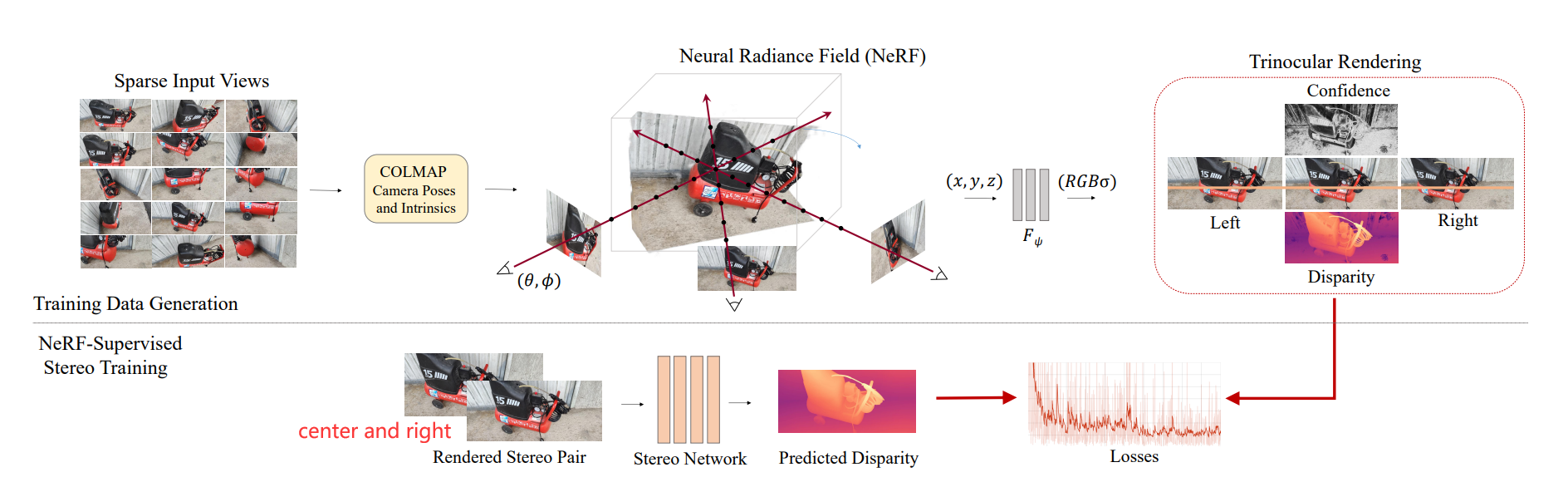
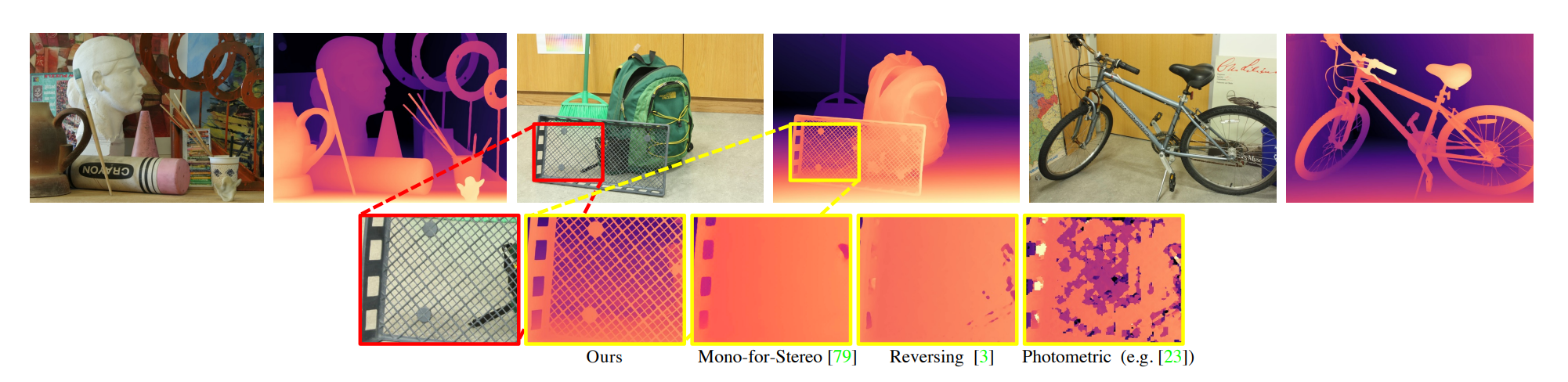
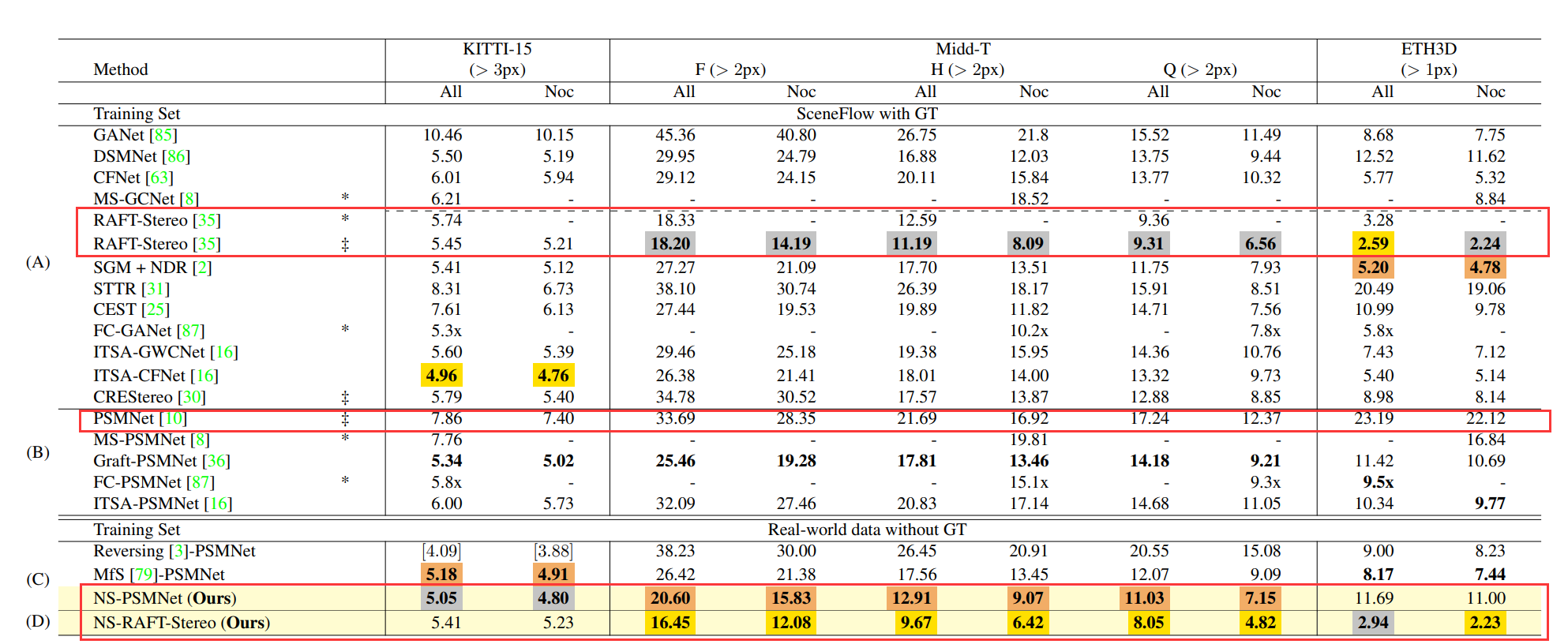
本文方法可用在其它任意深度立体匹配的模型中。比如下图中的PMSNet和NS-PMSNet,后者表示在PMSNet的基础上,通过本文基于NeRF-Supervised(NS)产生的数据进行监督训练所获得的结果。
Zero-Shot Generalization Results.(零样本泛化结果)